
Data mesh has been generating a lot of buzz recently in the business intelligence world. This is because businesses are always trying to improve and scale. Due to its scalability and democratization features, data mesh can massively help with data requirements for your business and meet your increasing needs. It’s a relatively new concept that continues to produce optimal outcomes when data is concerned. Although, its true potential has not been reached yet. Continuous modifications are enhancing the data platform architecture to obtain new heights to its power.
What is a Data Mesh?
In simplistic terms, data mesh is a paradigm that is both architectural and organizational. It’s an innovative way to prove that massive amounts of analytical data don’t need to be centralized or can only be used by a specialized team to gain the necessary value from the information.
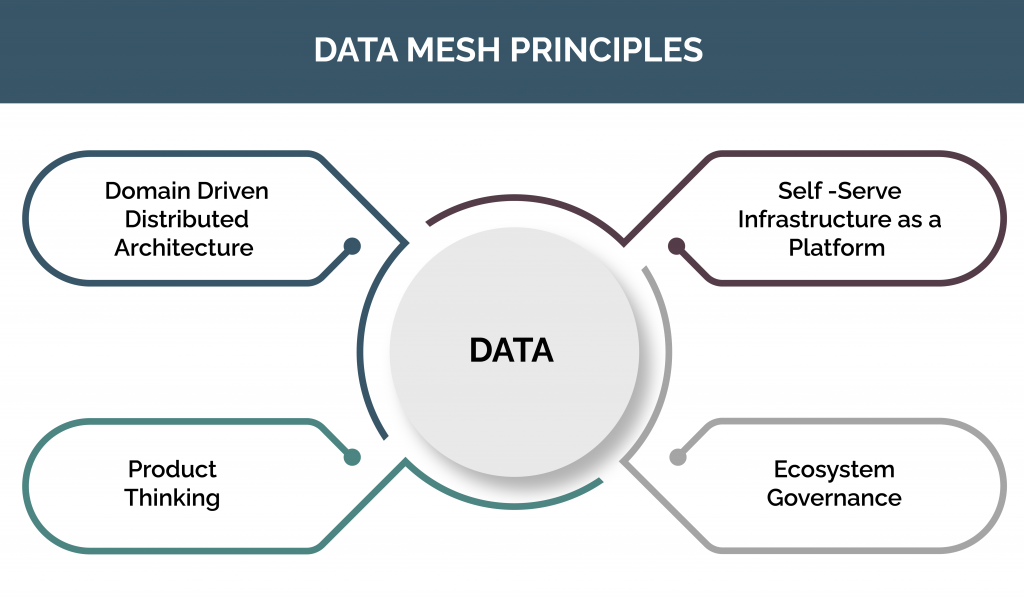
There are four main principles that this paradigm follows:
- Decentralization of architecture and data ownership that is domain-oriented
- Focus on data provided as a product that is domain-oriented
- Supporting self-serve data infrastructure by using a platform that promotes the use of autonomous, domain-oriented data teams.
- Ecosystems and interoperability are achieved by federated governance.
Why choose a Data Mesh?
There are many benefits as to why businesses should use a data mesh. If a company is looking to become data-driven, data mesh helps increase customer personalization and improve customer experience. Not only does it drastically increase efficiency by reducing your operational costs and employee time, but it also gives more in-depth business intelligence insights.
If you have a large number of domains, the data process can be highly complicated. For domain-based data ownership products that have been federated, a data mesh helps automate the right strategies to make it as efficient as possible. Thus, a data mesh is an essential step in improving the democratization of crucial data.
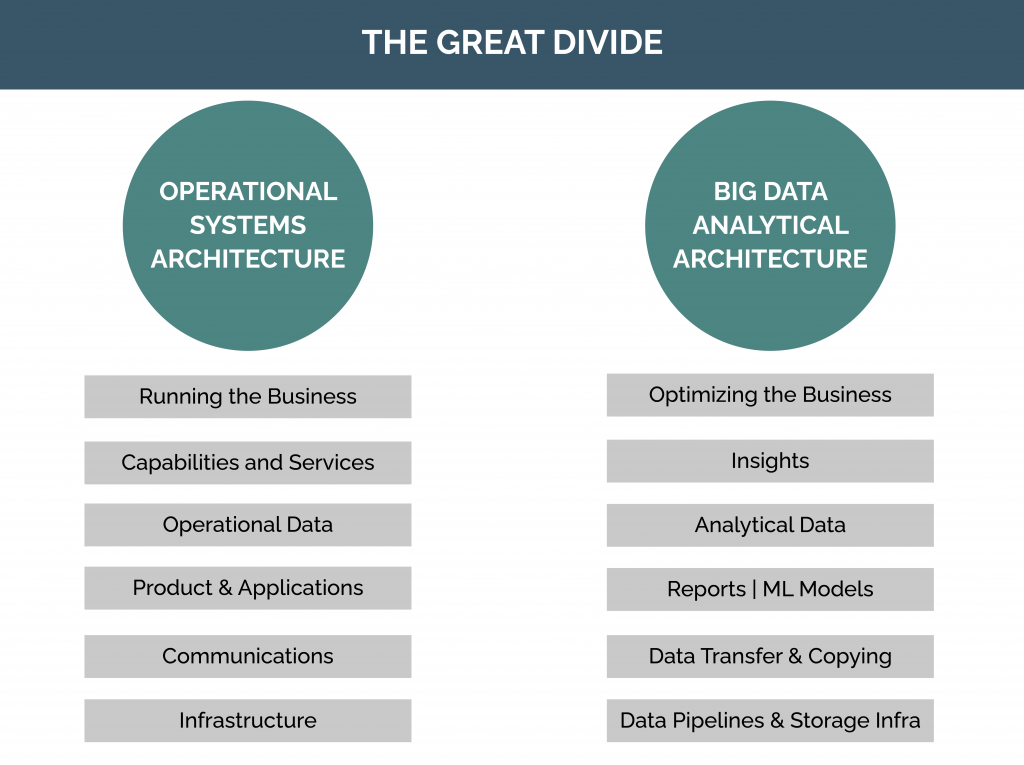
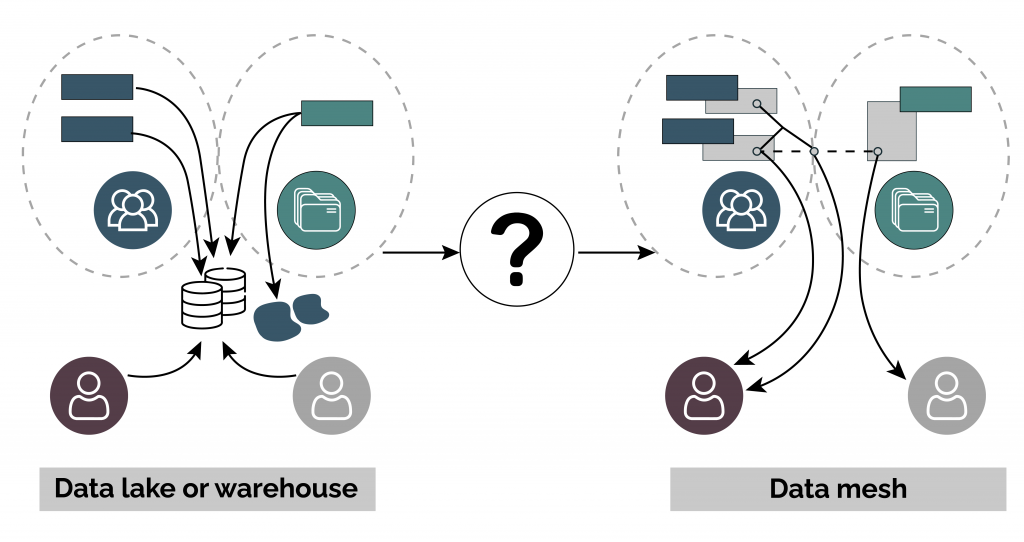
Data Lakes vs. Data Mesh: What’s the difference?
Data lakes are great if you are looking for one centralized system to complete all your data needs. However, data lakes can hold you back in achieving your goals when you scale your business. This is where a data mesh comes into play. A data mesh system gives employees more control over large amounts of data. However, as data is used for various things, having a less centralized system is necessary to complete data transformations in the most efficient way possible. Data lakes are great for smaller organizations. However, for larger companies that need lots of data to be processed, a data mesh is required to speed up their processes through autonomy and a more flexible system. This saves tons of time for data teams, giving those using this system a distinct edge over their competitors.
What’s a Data Mesh score?
A data mesh score is mainly based on how complicated your processes are. It also applies to how many systems or domains you have, the size of your data team, and the priority of data governance. If you have a high data mesh score, this means that your current processes would best benefit from using a data mesh.
Observability for Data Mesh
By measuring the internal states of a system by examining what is produced, businesses can analyze chains with more control and identify crucial elements. Data mesh helps ensure domain ownership when observability is concerned and offers these benefits by using self-serve capabilities:
- Quality metrics in data product
- Encryption for data at rest and in motion
- Monitoring, alerting, and logging in data product
- Data product schema
- Data production lineage
- Discovery, catalog registration, and publishing in data product
- Data governance and standardization
These core standardizations help give businesses high-end observability when utilized. Furthermore, it provides the ability to scale individual domains throughout the entire observability process.
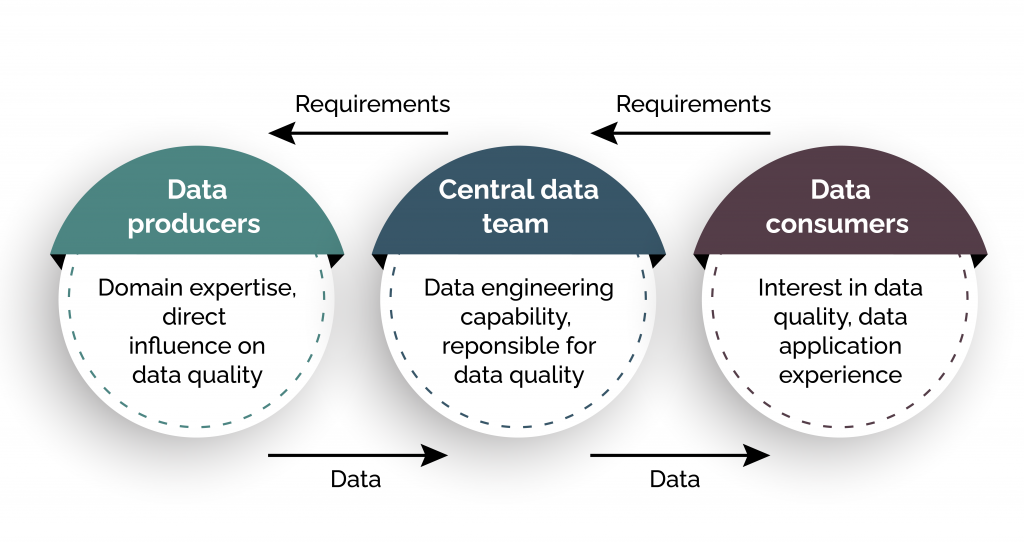
Data as a product using Data Mesh
This is achieved through the ownership of data being federated to domain data owners, providing more control and allowing them to hold accountability when supplying data as products. However, during this process, owners are supported by self-serve data platforms to reduce the technical knowledge needed for data mesh to work.
In addition, a new system of federated governance that is automated to ensure interoperability of data products that are domain-oriented is required. All these factors allow data to be decentralized, helping enhance the experience received by data consumers. Businesses that maintain a high pool of domains that require various systems and teams to produce data can benefit from data mesh, along with those with a range of set data-driven access patterns and use cases.
Challenges of Data Mesh
Although the current data mesh has tons of benefits, there are currently a few challenges that you may face. Many domain experts are not knowledgeable in using the specific domain programming languages which the data mesh may be using. On top of this, many programs in the data mesh are not API compatible. This can sometimes make it difficult for some businesses to complete their required tasks efficiently.
Putting Data Mesh 2.0 into practice
Digital transformation can be a complex process, primarily when data mesh is implemented on large networks. However, with version 2.0 coming soon, many of its advantages will cancel out many of the current challenges of Data Mesh 1.0 while significantly improving network processes. For more information on ensuring a smooth process, contact us today.


